MySQL基础回顾
操作数据库
- 操作数据库 > 操作数据库中的表 > 操作数据库表中的数据
- MySQL关键字不分区大小写
操作语句分类
| 名称 | 解释 | 命令 |
|---|---|---|
| DDL(定义语言) | 定义和管理数据库,数据表 | create,drop,alter |
| DML(数据操作语言) | 用于操作数据库对象中所包含的数据 | insert,update,delete |
| DQL(数据查询语言) | 查询数据 | selete |
| DCL(数据控制语言) | 管理数据权及数据更改 | grant,commit,roolback |
数据类型
MySQL 提供了丰富的数据类型,用于定义表中的列(字段)可以存储的数据类型。合理选择数据类型可以提高数据库的性能、节省存储空间,并确保数据的准确性。以下是 MySQL 中常见的数据类型分类及其详细说明:
1. 数值类型
用于存储数值数据,包括整数和浮点数。
1.1 整数类型
| 数据类型 | 存储空间 | 有符号范围 | 无符号范围 |
|---|---|---|---|
TINYINT |
1 字节 | -128 到 127 | 0 到 255 |
SMALLINT |
2 字节 | -32,768 到 32,767 | 0 到 65,535 |
MEDIUMINT |
3 字节 | -8,388,608 到 8,388,607 | 0 到 16,777,215 |
INT |
4 字节 | -2,147,483,648 到 2,147,483,647 | 0 到 4,294,967,295 |
BIGINT |
8 字节 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 | 0 到 18,446,744,073,709,551,615 |
示例:
1 | |
1.2 浮点数类型
| 数据类型 | 存储空间 | 描述 |
|---|---|---|
FLOAT |
4 字节 | 单精度浮点数,精度约 7 位小数 |
DOUBLE |
8 字节 | 双精度浮点数,精度约 15 位小数 |
DECIMAL(M,D) |
可变 | 精确小数,M 为总位数,D 为小数位数 |
示例:
1 | |
2. 字符串类型
用于存储文本数据。
| 数据类型 | 描述 |
|---|---|
CHAR(N) |
固定长度字符串,最多 255 个字符 |
VARCHAR(N) |
可变长度字符串,最多 65,535 个字符 |
2.3 文本类型
| 数据类型 | 描述 |
|---|---|
TINYTEXT |
最大长度 255 字节 |
TEXT |
最大长度 65,535 字节 |
MEDIUMTEXT |
最大长度 16,777,215 字节 |
LONGTEXT |
最大长度 4,294,967,295 字节 |
示例:
1 | |
3. 日期和时间类型
用于存储日期和时间数据。
| 数据类型 | 描述 |
|---|---|
DATE |
日期,格式:YYYY-MM-DD |
TIME |
时间,格式:HH:MM:SS |
DATETIME |
日期和时间,格式:YYYY-MM-DD HH:MM:SS |
TIMESTAMP |
时间戳,范围:1970-01-01 00:00:01 到 2038-01-19 03:14:07 |
YEAR |
年份,格式:YYYY |
示例:
1 | |
4. 二进制类型
用于存储二进制数据(如图片、文件等)。
| 数据类型 | 描述 |
|---|---|
BINARY(N) |
固定长度二进制数据,最多 255 字节 |
VARBINARY(N) |
可变长度二进制数据,最多 65,535 字节 |
TINYBLOB |
最大长度 255 字节 |
BLOB |
最大长度 65,535 字节 |
MEDIUMBLOB |
最大长度 16,777,215 字节 |
LONGBLOB |
最大长度 4,294,967,295 字节 |
6. JSON 类型
用于存储 JSON 格式的数据。
| 数据类型 | 描述 |
|---|---|
JSON |
存储 JSON 数据 |
示例:
1 | |
7. 选择数据类型的建议
- 尽量使用最小的数据类型:节省存储空间,提高性能。
- 例如,如果字段值范围在 0 到 255 之间,使用
TINYINT UNSIGNED而不是INT。
- 例如,如果字段值范围在 0 到 255 之间,使用
- 避免使用过大的字符串类型:根据实际需求选择
VARCHAR的长度。 - 使用
DECIMAL存储精确小数:避免浮点数精度问题。 - 使用
DATETIME或TIMESTAMP存储日期和时间:DATETIME支持更大的范围。TIMESTAMP占用更少的存储空间,但范围较小。
- 使用
JSON存储结构化数据:适用于动态字段的场景。 TEXT可以存储大量的Unicode字符,包括汉字等非ASCII字符
数据字段属性
- UnSigned : 无符号的,声明该数据列不允许负数 ;
- zerofill: 不足位数的用0来填充 , 如int(3),5则为005
- Auto_InCrement : 自增
- NULL 和 NOT NULL: 默认为NULL , 即没有插入该列的数值。如果设置为NOT NULL , 则该列必须有值
- DEFAULT:用于设置默认值
DML语言
Insert
1 | |
update
筛选条件 ,如不指定则修改该表的所有列数据
1 | |
筛选条件
| 运算符 | 范围 |
|---|---|
| = | 5=6 |
| != | 5!=6 |
| > | 5>3 |
| < | 3<4 |
| >= | 3>=4 |
| between | between 6 and 10 |
| and | 5>1 and 8 >2 |
| or | 5>1 or 8 >2 |
delete
筛选条件 , 如不指定则删除该表的所有列数据
1 | |
truncate
作用:用于完全清空表数据 , 但表结构 , 索引 , 约束等不变 ;
1 | |
truncate 与 delete 区别
- 相同 : 都能删除数据 , 不删除表结构 , 但TRUNCATE速度更快
- 不同 :
- 使用TRUNCATE TABLE 重新设置AUTO_INCREMENT计数器
- 使用TRUNCATE TABLE不会对事务有影响 (事务后面会说)
DQL语言-Select
1 | |
注意: [ ] 括号代表可选的 , { }括号代表必选得
使用
1 | |
连接查询
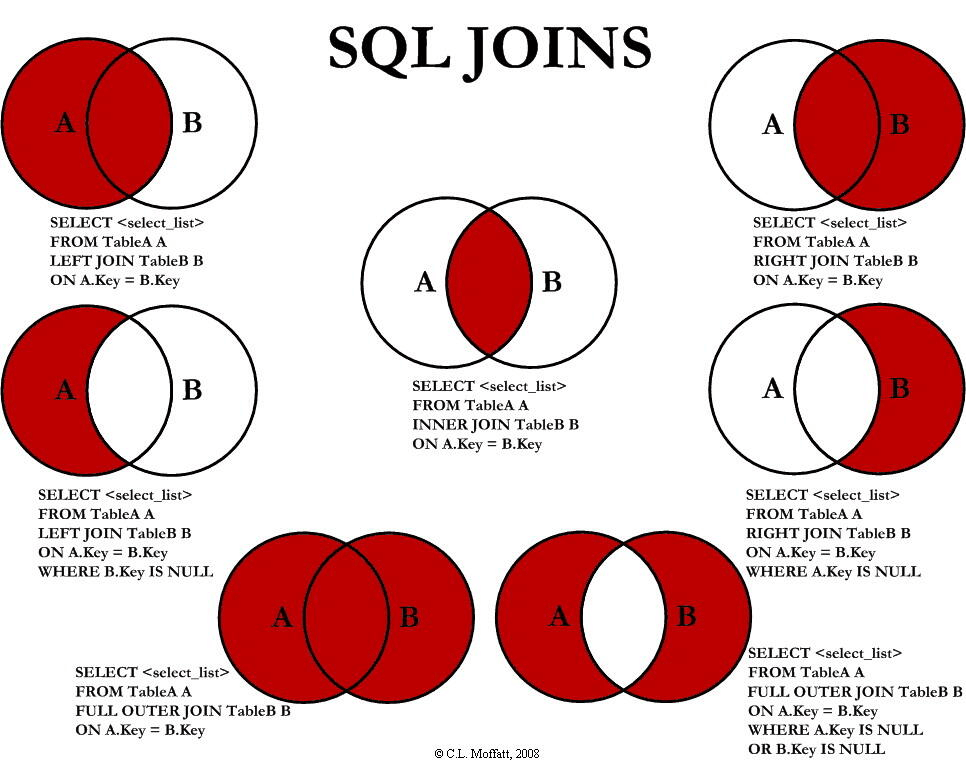
分类一:
- inner join : 两个表的交集,使用时
INNER关键字是可以省略的 - outer join
- left join:以左表作为基准,右边表来一一匹配,匹配不上的,返回左表的记录,右表以NULL填充
- right join 以右表作为基准,左边表来一一匹配,匹配不上的,返回右表的记录,左表以NULL填充
- MySQL 不支持
FULL JOIN(全外连接)。如果你需要实现类似于FULL JOIN的功能,可以通过UNION结合LEFT JOIN和RIGHT JOIN来模拟。
分类二:
| 连接类型 | 描述 | 使用场景 |
|---|---|---|
| 等值连接 | 连接条件使用等号(=) | 基于列值相等的查询 |
| 非等值连接 | 连接条件使用非等号运算符(>、< 等) | 范围查询或复杂逻辑条件 |
| 自连接 | 表与自身连接 | 处理层次结构或递归关系的数据 |
1 | |
多张表连接时,表与表之间关系是并列关系
排序和分页
- ORDER BY :用于根据指定的列对结果集进行排序。
- 默认按照ASC升序。
- 如果希望降序使用 DESC 关键字。
- limit [页数],[页中条数]
1 | |
子查询
在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句;
嵌套查询可由多个子查询组成,求解的方式是由里及外;
子查询返回的结果一般都是集合,故而建议使用IN关键字;
1 | |
MySQL 常用函数
数学函数
1 | |
字符串函数
1 | |
日期函数
1 | |
聚合函数
1 | |
分组和过滤
where写在group by前面.;
要是放在 GROUP BY 的筛选要使用HAVING。
1 | |
查询语句的执行顺序
关键执行顺序:FROM → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT。
MySQL 执行查询语句的顺序与书写顺序不同,具体如下:
FROM users:从users表中读取数据。JOIN orders ON users.id = orders.user_id:将users表和orders表连接。WHERE users.age > 18:过滤出年龄大于 18 的用户。GROUP BY users.country:按国家分组。HAVING user_count > 10:过滤出用户数大于 10 的国家。SELECT users.country, COUNT(*) AS user_count:选择国家列并计算用户数。ORDER BY user_count DESC:按用户数降序排序。LIMIT 5:返回前 5 行。
事务
- 事务就是将一组SQL语句放在同一批次内去执行;
- 如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行;
- MySQL事务处理只支持
InnoDB和BDB数据表类型
ACID原则
- 原子性(Atomic): 要不不执行,要不一起执行
- 一致性(Consistency):事务操作数据前后,数据的状态是由一个有效状态到另外一个有效状态;
- A 和 B,需要从 A 转账 100 元到 B。转账前后,A 和 B 账户的总金额不变。 如果 A 账户余额不足,事务应失败,确保不会出现负数余额。
- 隔离性(Isolated) : 多个并发事务之间要相互隔离;
- 读未提交 : 事务能读取其他事务未提交的数据。
- 读已提交 : 事务只能读取其他已提交事务的数据。【默认】
- 可重复读 : 它确保在同一个事务中,多次读取同一数据时,结果是一致的;无法杜绝幻读
- 串行化:事务一个一个的执行
- 持久性(Durability) : 事务对数据库所作的修改持久的保存在数据库之中。
并发问题
- 脏读(Dirty Read):一个事务读取了另一个未提交事务的数据。
- 不可重复读(Non-Repeatable Read):一个事务多次读取同一数据,结果不一致。—— 针对单一数据
- 幻读(Phantom Read):一个事务多次查询同一范围的数据,结果集不一致。—— 针对范围数据
幻读与不可重复读的区别
| 问题类型 | 描述 | 操作 |
|---|---|---|
| 幻读 | 同一查询返回的结果集不一致(新增数据) | 插入操作 |
| 不可重复读 | 同一数据行的值不一致 | 更新或删除操作 |
隔离级别与并发问题
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(Non-Repeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|
| 读未提交 | 可能 | 可能 | 可能 |
| 读已提交 | 不可能 | 可能 | 可能 |
| 可重复读 | 不可能 | 不可能 | 可能 |
| 串行化 | 不可能 | 不可能 | 不可能 |
语法
1 | |
索引
索引(Index)是帮助MySQL高效获取数据的数据结构;
分类
- 主键索引 (Primary Key):唯一的标识,主键不可重复,只能有一个列作为主键
- 主键索引只能有一个
- 唯一索引 (Unique Key): 避免重复的列出现,唯一索引可以重复,多个列都可以标识位唯一索引
- 唯一索引可能有多个
- 常规索引 (Index) : 默认的, index。key关键字来设置
- 全文索引 (FullText) : 在特定的数据库引擎下才有, MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
- 只能用于CHAR , VARCHAR , TEXT数据列类型
- 适合大型数据集
1 | |
常规索引
作用 : 快速定位特定数据
- index 和 key 关键字都可以设置常规索引
- 应加在查询找条件的字段
- 不宜添加太多常规索引,影响数据的插入,删除和修改操作
1 | |
全文索引
作用 : 快速定位特定数据
注意 :
- 只能用于MyISAM类型的数据表
- 只能用于CHAR , VARCHAR , TEXT数据列类型
- 适合大型数据集
1 | |
MySQL基础回顾
https://stuartyang.site/2025/03/18/MySQL基础回顾/